

文档首页/
AI开发平台ModelArts/
最佳实践/
LLM大语言模型训练/
LLM大语言模型训练历史版本文档/
主流开源大模型基于ModelArts Standard&Lite Server适配AscendFactory PyTorch NPU训练指导(6.5.905)/
准备工作/
ModelArts Standard/
准备数据、权重和代码
更新时间:2025-07-29 GMT+08:00
准备数据、权重和代码
ModelArts Standard弹性集群运行环境中存储分为OBS桶和SFS Turbo共享盘,根据存储的不同,数据上传地址有差异,客户根据实际选择。
OBS桶
- 本地完成代码包AscendCloud-LLM-xxx.zip的解压。
# Linux系统 unzip AscendCloud-*.zip && unzip AscendCloud-LLM-*.zip && unzip ./llm_train/AscendFactory/data.tgz
- 上传权重。
- 获取对应模型的权重文件,获取链接参考支持的模型列表,并检查权重文件、大小是否完整。
- 本地修改权重(tokenizer)文件,以下模型需修改,根据所选框架及模型修改相应文件,详情参考tokenizer文件说明
- Llama-Factory:glm4-9B模型、InternVL2_5系列模型
- 在创建OBS桶创建的桶下创建文件夹用以存放权重和词表文件,例如在桶standard-llama2-13b中创建文件夹llama2-13B-chat-hf。
- 利用OBS-Browser+工具将下载好的权重文件上传至创建的文件夹目录下。得到OBS下数据集结构,此处以llama2-13B为例(权重文件可能变化,以下仅为举例)。
- 上传代码及数据。
- 准备数据集,例如下载样例数据集或者在本地按照固定格式处理好自己的数据集(可参考数据说明),并将数据集存放至本地llm_train/AscendFactory/data目录下。
- 【VeRL框架】数据预处理:
- 根据模型类型选择VeRL数据处理样例脚本内容拷贝至本地为dataset_demo.py,编辑脚本中dataset = datasets.load_dataset(xxx/xxx/xxx)的xxx/xxx/xxx值,填写原始数据集目录或文件的绝对或相对路径。
- 本地执行以下命令:
python dataset_demo.py --local_dir=llm_train/AscendFactory/data/xxx
- --local_dir:数据处理输出后的数据集路径
- 是否使用Llama-Factory框架训练。
- 是,更新data/dataset_info.json文件。如使用以下示例数据集则命令如下。关于数据集文件格式及配置,更多样例格式信息请参考README_zh.md 的内容。
vim dataset_info.json
新加配置参数如下:
"alpaca_gpt4_data": { "file_name": "alpaca_gpt4_data.json" },样例截图:
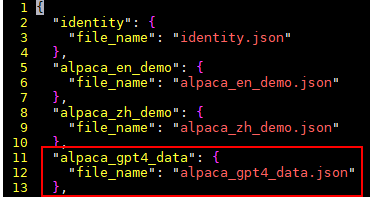
- 否,执行下一步。
- 是,更新data/dataset_info.json文件。如使用以下示例数据集则命令如下。关于数据集文件格式及配置,更多样例格式信息请参考README_zh.md 的内容。
- 利用OBS Browser+工具将llm_train文件夹上传至OBS中
SFS Turbo共享盘
- 获取权重:
- 获取对应模型的权重文件,获取链接参考支持的模型列表,并检查权重文件、大小是否完整。
- 本地修改权重(tokenizer)文件,以下模型需修改,根据所选框架及模型修改相应文件,详情参考tokenizer文件说明
- Llama-Factory:glm4-9B模型、InternVL2_5系列模型
- 通过以下两种方式将下载到本地的模型文件上传至SFS Turbo中。方式一操作简单,但是数据传输速度比较慢,费时间。方式二操作相对方式一复杂一些,但是数据传输速度较快。
方式一:将已下载的模型文件通过拖拽文件的方式,上传文件。使用CloudShell或者其它SSH远程工具上传至SFS Turbo中。具体步骤如下:
方式二:通过OBS Browser+将数据上传至OBS,最后在ECS中使用obsutil工具将OBS数据下载至SFS Turbo中。具体步骤如下:
- 在创建OBS桶创建的桶下创建文件夹用以存放模型,例如在桶standard-llama2-13b中创建文件夹model/llama-2-13b-hf。
- 利用OBS Browser+工具将下载的模型文件上传至创建的文件夹目录下。
- 在ECS服务器中安装obsutil工具,具体命令可参考obsutil工具快速使用,将OBS桶中的数据下载至SFS Turbo中。注意:需要使用用户账号中的AK和SK进行签名验证,确保通过授权的账号才能访问指定的OBS资源。
- 代码准备及上传:
将AscendFactory代码包:AscendCloud-LLM-xxx.zip直接上传至ECS服务器中的SFS Turbo中,例如存放在/mnt/sfs_turbo目录,进入此目录并解压代码包。
cd /mnt/sfs_turbo && unzip AscendCloud-*.zip && unzip AscendCloud-LLM-*.zip && unzip ./llm_train/AscendFactory/data.tgz
- 数据下载及更新
- 将下载样例数据集或者在本地按照固定格式处理好自己的数据集(可参考数据说明)存放至第2步解压完成的代码包llm_train/AscendFactory/data目录下。
- 【VeRL框架】数据预处理:
- 根据模型类型选择VeRL数据处理样例脚本内容拷贝至本地为dataset_demo.py,编辑脚本中dataset = datasets.load_dataset(xxx/xxx/xxx)的xxx/xxx/xxx值,填写原始数据集目录或文件的绝对或相对路径。
- 本地执行以下命令:
python dataset_demo.py --local_dir=llm_train/AscendFactory/data/xxx
--local_dir:数据处理输出后的数据集路径。
- 【Llama-Factory框架训练】更新data/dataset_info.json文件。示例数据集命令如下。关于数据集文件格式及配置,更多样例格式信息请参考README_zh.md 的内容。
vim dataset_info.json
新加配置参数如下:
"alpaca_gpt4_data": { "file_name": "alpaca_gpt4_data.json" },样例截图:
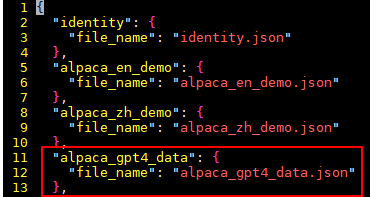
- 数据准备及上传:
可通过两种方式。可通过两种方式,将数据集上传至SFS Turbo中。
方式一:将下载的原始数据通过SSH直接上传至SFS Turbo的llm_train/AscendFactory/data目录中。
方式二:通过OBS Browser+将数据上传至OBS,最后在ECS中使用obsutil工具将OBS数据下载至SFS Turbo中。具体步骤如下:
- 利用OBS Browser+工具将数据集上传至obs://<bucket_name>/llm_train/xxx/data目录下
- 在ECS服务器中安装obsutil工具,具体命令可参考obsutil工具快速使用,将OBS桶中的数据下载至SFS Turbo中。注意:需要使用用户账号中的AK和SK进行签名验证,确保通过授权的账号才能访问指定的OBS资源。
父主题: ModelArts Standard




